Naviguer vers les autres articles du dossier :
- #1 Implements DevOps >> Lire l’article >
- #3 Risque et budget d’erreur >> Lire l’article >
- #4 Allez plus loin dans le SRE >> Lire l’article >
Une équipe responsable du Maintien en Condition Opérationnel (MCO) passe son temps à éteindre des incendies, dont beaucoup proviennent de bugs applicatifs. Foncièrement, développeurs et opérateurs ne sont pas d’accord sur la manière d’assurer la fiabilité d’un service. Alors, comment manager les niveaux de service (service levels) ?
Comment proposer de nouvelles fonctionnalités et en retirer d’autres tout en garantissant les niveaux de service ?
C’est un problème DevOps classique à tel point qu’il préoccupait déjà Google au début des années 2000. C’était l’époque même du développement du moteur de recherche. C’est dire l’enjeu de la problématique. Google a initié le SRE pour apporter une réponse efficace à cela. Depuis, cette discipline est en constante amélioration.
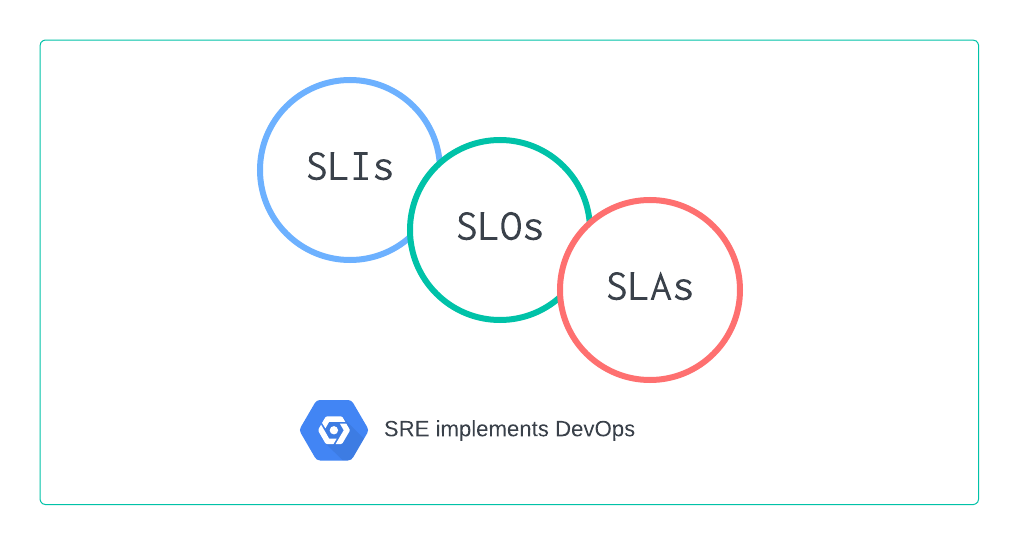
En effet, le SRE propose de résoudre le problème de trois manières différentes :
- il définit ce qu’est la disponibilité (SLI) ;
- il établit ce qu’est le niveau de disponibilité approprié (SLO) ;
- il met en cohérence les méthodes applicables si ces normes n’étaient pas respectées (SLA).
Pour que cela fonctionne, avant tout, c’est toute l’organisation qui doit connaitre ces définitions et ces règles. Des développeurs de produits aux SRE, ou des contributeurs individuels jusqu’aux vice-présidents, tout le monde doit partager le sentiment de responsabilité à l’égard du service. En définissant des objectifs de niveau de service (SLO) en collaboration avec les Product Owners (PO), les risques de confusion et de conflit diminuent naturellement.
En fin de compte, un SLO est un simple accord entre les parties prenantes sur la fiabilité d’un service.
Pourquoi ne pas viser une fiabilité de 100 %
La réalité montre que le coût et la complexité technique nécessaires pour rendre les services plus fiables deviennent de plus en plus élevés à mesure que l’on s’approche de 100 %. Il s’avère aussi que l’exigence des utilisateurs n’atteint pas une fiabilité parfaite. Cela signifie qu’il existe une marge d’erreur pour déployer des fonctionnalités de manière fiable.
Comment rendre un service raisonnablement fiable ?
En premier lieu, il est essentiel de placer le concept de disponibilité dans le contexte du service en particulier.
Quels indicateurs numériques clairs peuvent décrire cette disponibilité ?
Souvent les SLI sont des mesures au fil du temps, telles que la latence des requêtes, le débit des requêtes par seconde dans le cas d’un système par batch ou les échecs par nombre total de requêtes. Ils sont généralement regroupés par période, sur lesquelles on peut appliquer une fonction telle qu’un percentile (comme un 99e percentile ou une médiane). De cette façon, on met en lumière un seuil concret comme étant un nombre unique, bon ou mauvais. Par exemple, un bon indicateur pourrait déterminer :
- que la latence du 99e percentile des requêtes reçues au cours des cinq dernières minutes est inférieure à 300 millisecondes ;
- ou bien, que le ratio d’erreurs par rapport au total des demandes reçues au cours des cinq dernières minutes est inférieur à 1 %.
Comment passe-t-on du SLI au SLO ?
Un SLI indique à tout moment si le service est « disponible » ou « en panne ». Donc, pour avoir une vue globale, il suffit de faire la somme de toutes les valeurs du SLI sur une période plus longue, comme un an. La disponibilité totale sur cette période est au-dessus ou en deçà de ce qui est acceptable pour le service. Ce seuil sur une période longue est le SLO.
En tout état de cause, c’est l’équipe produit qui décide de l’objectif explicite de disponibilité de son service.
Doit-on toujours battre un SLO ?
En fait, les SLO sont à la fois des limites supérieure et inférieure. Cela pour deux raisons :
- Si on cherche à rendre un service beaucoup plus fiable que nécessaire, les efforts passés à la fiabilisation entraînent mécaniquement le ralentissement, voir l’arrêt, de la publication de nouvelles fonctionnalités. Alors que ces nouvelles fonctionnalités auraient pu augmenter la satisfaction de l’utilisateur de manière plus significative que la recherche d’une fiabilité sans faille.
- Mais si on ne cherche pas à être confortablement au-dessus du SLO, alors la qualité de service sera, au mieux, tout juste satisfaisante (temporairement insatisfaisante). Les utilisateurs risquent de se tourner vers un service concurrent.
Qu’est-ce qu’apporte le SLA ?
Le SLA est un accord commercial qui décrit les mesures correctives à prendre si le service rendu n’est pas conforme aux spécifications du contrat. Un SLA est relié à un SLO. Il décrit l’ensemble des services et des promesses de disponibilité qu’un fournisseur est prêt à faire à un client. Surtout, il y associe les mesures associées au non-respect de ces promesses. Ces mesures pourraient être, par exemple, un remboursement ou un geste commercial, comme des crédits offerts.
D’ailleurs, il n’est pas prudent de fixer les seuils identiques entre SLO et SLA. En effet, pour laisser une marge entre l’objectif visé et la limite contractuelle, le SLO à tout intérêt à être plus stricte que le SLA. Inversement, le SLA doit laisser de la clémence par rapport au SLO. L’idée est d’avoir une liberté d’action avant d’être confronté à la « sanction ».
Logiquement, un SRE se concentrera sur les SLO, étant entendu que les équipes commerciales et les équipes commerciales réfléchiront davantage aux SLA qu’elles doivent construire par rapport aux SLO.
Donc, pour résumer, les SLI sont des indicateurs de niveau de service, ou des mesures supplémentaires qui renseignent sur la santé d’un service. Les SLO sont les objectifs de niveau de service qui sont convenus. Les SLA décrivent la contrepartie en cas de non-respect des SLO.
Sources
1) Google Cloud Summit France, 2023. Consulté sur https://cloudonair.withgoogle.com/events/summit-france-2023
2) Fong-Jones, L. et Vargo, S. (2018). « SLIs, SLOs, SLAs, oh my! (class SRE implements DevOps) », dans Google Cloud Tech, Youtube. Consulté en septembre 2023 sur https://youtu.be/tEylFyxbDLE?si=k1y1t4U-YF4PNFIa